
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- docker로 airflow 설치하기
- leetcode 234
- Hadoop
- 머신러닝
- Python
- 올바른 변수명 짓기
- leetcode
- webcrawler
- leetcode 49
- wargame.kr
- airflow docker
- leetcode 5
- leetcode 561
- Hortonworks Sandbox
- 블로그 이전했어요
- leetcode 238
- 데이터레이크와 데이터웨어하우스
- leetcode125
- ctf-d
- 컴퓨터구조
- leetcode 121
- 문자열 조작
- leetcode 819
- 빅데이터를 지탱하는 기술
- 스파크 완벽 가이드
- MapReduce 실습
- leetcode 937
- 배열
- leetcode 15
- leetcode 344
- Today
- Total
HyeM
[Do it-Ch05] l1,l2 규제와 교차 검증 본문
05-3. 규제 방법을 배우고 단일층 신경망에 적용합니다
규제 : 과대적합을 해결하기 위한 대표적인 방법
- 가중치를 규제하면 모델의 일반화 성능이 올라감
- 가중치를 제한하면 모델이 몇 개의 데이터에 집착하지 않아 일반화 성능을 높일 수 있음
- 대표적인 규제 기법에는 L1 규제와 L2 규제가 있음
- L2 규제가 더 효과가 좋아 널리 사용됨
L1 규제 : 라쏘 모델
w_grad += alpha * np.sign(w)
L2 규제 : 릿지 모델
w_grad += alpha * w
대표적인 규제기법인 L1규제와 L2 규제를 살펴보고, SingleLayer 클래스에 적용시켜보자.
class SingleLayer:
'''
그레이디언트 업데이트 수식에 패널티 항 반영하기
: L1, l2 규제의 강도를 조절하는 매개변수 추가
'''
def __init__(self, learning_rate=0.1, l1=0, l2=0):
self.w = None
self.b = None
self.losses = []
self.val_losses = []
self.w_history = []
self.lr = learning_rate
self.l1 = l1
self.l2 = l2
'''
역방향 계상 수행 시, 그레이디언트 패널티 항의 미분값을 더함
L1,L2 규제를 따로 적용하지 않고, 동시에 적용함
'''
def fit(self, x, y, epochs=100, x_val=None, y_val=None):
self.w = np.ones(x.shape[1]) # 가중치 초기화
self.b = 0 # 절편 초기화
self.w_history.append(self.w.copy()) # 가중치 기록
np.random.seed(42) # 랜덤 시드
for i in range(epochs): # epochs만큼 반복.
loss = 0
indexes = np.random.permutation(np.arange(len(x))) # 인덱스 섞기
for i in indexes: # 모든 샘플에 대해 반복
z = self.forpass(x[i]) # 정방향 계산
a = self.activation(z) # 활성화 함수 적용
err = -(y[i] - a) # 오차 계산
w_grad, b_grad = self.backprop(x[i], err) # 역방향 계산
# 그래디언트에서 페널티 항의 미분 값을 더하기
w_grad += self.l1 * np.sign(self.w) + self.l2 * self.w
self.w -= self.lr * w_grad # 가중치 업데이트
self.b -= b_grad # 절편 업데이트
self.w_history.append(self.w.copy()) # 가중치 기록
# 안전한 로그 계산을 위해 클리핑한 후 손실 누적
a = np.clip(a, 1e-10, 1-1e-10)
loss += -(y[i]*np.log(a)+(1-y[i])*np.log(1-a))
self.losses.append(loss/len(y) + self.reg_loss()) # epoch마다 평균 손실을 저장
self.update_val_loss(x_val, y_val) # 검증 세트에 대한 손실 계산
'''
로지스틱 손실 함수 계산에 페널티 항 추가
reg_loss()는 훈련 세트의 로지스틱 소실 함수의 값과 검증세트의 로지스틱 손실 함수의 값을 계산할때 모두 호출됨
'''
def reg_loss(self):
return self.l1 * np.sum(np.abs(self.w)) + self.l2 / 2 * np.sum(self.w**2)
'''
검증 세트의 손실을 계산하는 update_val_loss() 메서드에서 reg_loss() 를 호출하도록 수정함
'''
def update_val_loss(self, x_val, y_val):
if x_val is None:
return
val_loss = 0
for i in range(len(x_val)):
z = self.forpass(x_val[i]) # 정방향 계산
a = self.activation(z) # 활성화 함수 적용
a = np.clip(a, 1e-10, 1-1e-10)
val_loss += -(y_val[i]*np.log(a)+(1-y_val[i])*np.log(1-a))
self.val_losses.append(val_loss/len(y_val) + self.reg_loss())
def forpass(self, x):
z = np.sum(x * self.w) + self.b # 직선 방정식을 계산합니다
return z
def backprop(self, x, err):
w_grad = x * err # 가중치에 대한 그래디언트를 계산합니다
b_grad = 1 * err # 절편에 대한 그래디언트를 계산합니다
return w_grad, b_grad
def activation(self, z):
z = np.clip(z, -100, None) # 안전한 np.exp() 계산을 위해
a = 1 / (1 + np.exp(-z)) # 시그모이드 계산
return a
def predict(self, x):
z = [self.forpass(x_i) for x_i in x] # 정방향 계산
return np.array(z) >= 0 # 스텝 함수 적용
def score(self, x, y):
return np.mean(self.predict(x) == y)
cancer = load_breast_cancer()
x = cancer.data
y = cancer.target
x_train_all, x_test, y_train_all, y_test = train_test_split(x, y, stratify=y,
test_size=0.2, random_state=42)
x_train, x_val, y_train, y_val = train_test_split(x_train_all, y_train_all, stratify=y_train_all,
test_size=0.2, random_state=42)
train_mean = np.mean(x_train, axis=0)
train_std = np.std(x_train, axis=0)
x_train_scaled = (x_train - train_mean) / train_std
val_mean = np.mean(x_val, axis=0)
val_std = np.std(x_val, axis=0)
x_val_scaled = (x_val - val_mean) / val_std
L1규제를 적용시켜보자.
# L1 규제
l1_list = [0.0001, 0.001, 0.01]
for l1 in l1_list:
lyr = SingleLayer(l1=l1)
lyr.fit(x_train_scaled, y_train, x_val=x_val_scaled, y_val=y_val)
plt.plot(lyr.losses)
plt.plot(lyr.val_losses)
plt.title('Learning Curve (l1={})'.format(l1))
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train_loss', 'val_loss'])
plt.ylim(0, 0.3)
plt.show()
plt.plot(lyr.w, 'bo')
plt.title('Weight (l1={})'.format(l1))
plt.ylabel('value')
plt.xlabel('weight')
plt.ylim(-4, 4)
plt.show()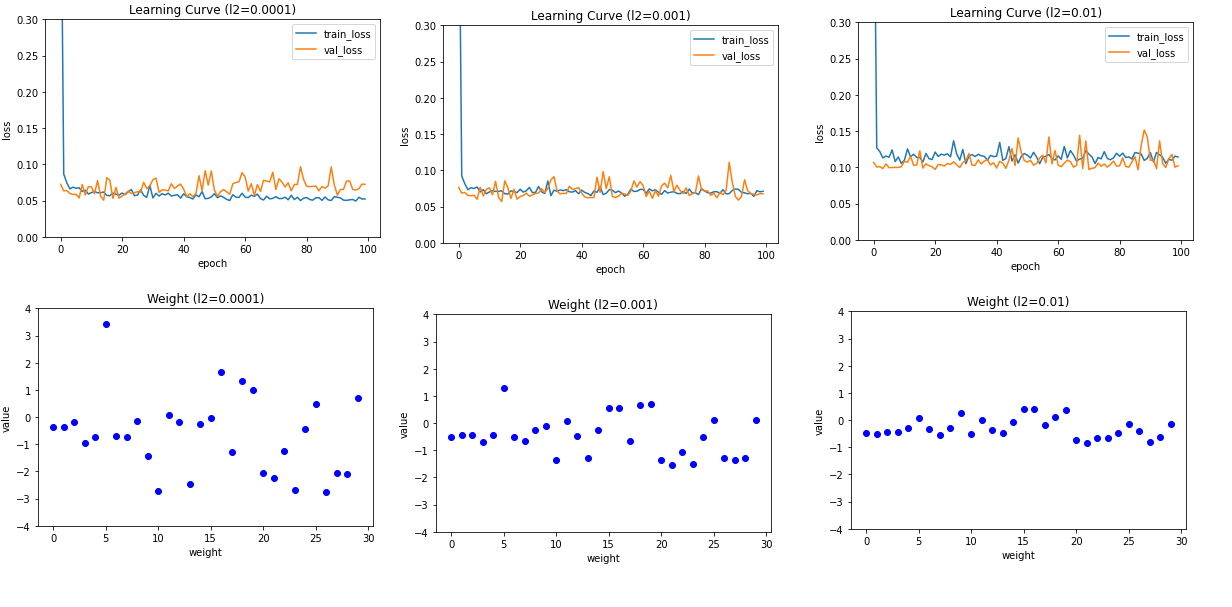
- 마지막 학습 곡선 그래프를 보면 l2규제는 규게 강도가 강해져도 l1 규제만큼 과소 적합이 심해지지는않음
- 가중치 그래프를 보면 가중치가 0에 너무 가깝게 줄어들지 않음


사이킷런 SGDClassifier 클래스도 l1규제, l2 규제를 지원함 결과는 SingleLayer 클래스의 결과와 동일함
05-4. 교차 검증을 알아보고 사이킷런으로 수행해 봅니다
교차 검증 : 전체 데이터 세트의 샘플 개수가 많지 않을때, 훈련세트의 샘플 개수가 줄어들어 모델을 훈련시킬 데이터가 부족해지는 경유에, 교차 검증에 사용됨
[ 교차 검증 과정, k-폴드 교차 검증 ]
- 훈련 세트의 k 개 폴드(fold)로 나눈다.
- 첫 번째 폴드를 검증 세트로 사용하고 나머지 폴드 (k-1)를 훈련 세트로 사용한다.
- 모델을 훈련한 다음에 검증 세트로 평가한다.
- 차례대로 다음 폴드를 검증 세트로 사용하여 반복한다.
- k개의 검증 세트로 k번 성능을 평가한 후 계산된 성능의 평균을 내어 최종 성능을 계산한다.
k-폴드 교차 검증 구현하기
k-폴드 교차 검증은 검증 세트가 훈련 세트에 포함된다. 따라 서 전체 데이터 세트를 다시 훈련세트와 테스트세트로 한 번만 나눈 x_train_all과 y_train_all을 훈련과 검증에 사용한다.
validation_scores = [] # 각 폴드의 검증 점수를 저장하기 위한 리스트k = 10
bins = len(x_train_all) // k # 한 폴드에 들어갈 샘플의 개수
for i in range(k):
start = i*bins # 검증 폴드 샘플의 시작 인덱스
end = (i+1)*bins # # 검증 폴드 샘플의 끝 인덱스
val_fold = x_train_all[start:end]
val_target = y_train_all[start:end]
# train_index에 list() 함수를 이용하여 훈련 폴드의 인덱스를 모아둠
train_index = list(range(0, start))+list(range(end, len(x_train_all)))
# 만든 훈련 폴드 샘플의 인덱스로 train_fold와 train_target을 만듦
train_fold = x_train_all[train_index]
train_target = y_train_all[train_index]
train_mean = np.mean(train_fold, axis=0)
train_std = np.std(train_fold, axis=0)
train_fold_scaled = (train_fold - train_mean) / train_std
val_fold_scaled = (val_fold - train_mean) / train_std
lyr = SingleLayer(l2=0.01)
lyr.fit(train_fold_scaled, train_target, epochs=50)
score = lyr.score(val_fold_scaled, val_target)
validation_scores.append(score)
print(np.mean(validation_scores))사이킷런으로 교차 검증하기
cross_validate() 함수로 교차 검증 점수 계산한다.
cross_validate()의 매개변수로는 교차 검증을 하고 싶은 모델의 객체와 훈련데이터, 타깃 데이터를 전달하고 cv 매개변수에 교차 검증을 수행할 폴드 수를 지정함

교차 검증의 평균 점수는 약 85%로 낮은 편이다. 이유는 표준화 전처리를 수행하지 않았기 때문이다.
전처리 단계를 포함해 교차 검증을 수행한다.
훈련 세트를 표준화 전처리 하기 전에 생각할 것은, 만약 훈련 세트 전체를 전처리 한 후에 cross_validate()함수에 매개변수 값으로 전달하면 검증 폴드가 표준화 전처리 단계에서 누설되므로, 새로운 방법을 찾아야한다.
StandardScaler 클래스의 객체와 앞에서 만든 SGDClassifier 클래스의 객체를 make_pipeline()함수에 전달하여 파이프라인 객체를 만들고, 그런 다음 교차 검증 점수를 출력한다.

평균 검증 점수가 높아졌다.
cross_validate() 함수에 return_train_score 매개변수를 true로 설정하면 훈련 폴드의 점수도 얻을 수 있다.
'Study > AI&DeepLearning' 카테고리의 다른 글
| [Do it-Ch06] 신경망 알고리즘 벡터화 (0) | 2021.06.25 |
|---|---|
| [Do it] 검증세트와 전처리 과정, 과대적합과 과소적합 (0) | 2021.06.02 |
| [Do it] 로지스틱 뉴런 단일층 신경망 구현, 사이킷런 로지스틱 회귀 수행 (0) | 2021.05.05 |
| [Do it] 로지스틱 회귀, 시그모이드 함수, 로지스틱 손실 함수 (0) | 2021.04.05 |
| [Do it] 3-3|3-4_선형회귀, 경사하강법 (0) | 2021.04.05 |



