
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
Tags
- 올바른 변수명 짓기
- leetcode 561
- MapReduce 실습
- Hortonworks Sandbox
- leetcode 238
- 문자열 조작
- Python
- leetcode 5
- 스파크 완벽 가이드
- 머신러닝
- ctf-d
- airflow docker
- leetcode 121
- leetcode125
- leetcode 49
- Hadoop
- 컴퓨터구조
- leetcode
- leetcode 937
- wargame.kr
- 배열
- leetcode 819
- leetcode 234
- leetcode 344
- webcrawler
- 빅데이터를 지탱하는 기술
- leetcode 15
- 데이터레이크와 데이터웨어하우스
- docker로 airflow 설치하기
- 블로그 이전했어요
Archives
- Today
- Total
HyeM
Evaluating & Prediction 본문
Evaluating & Prediction
▶사전 준비
더보기




1. import package
2. Build Model
▶ Proprocess
데이터 셋 불러오기
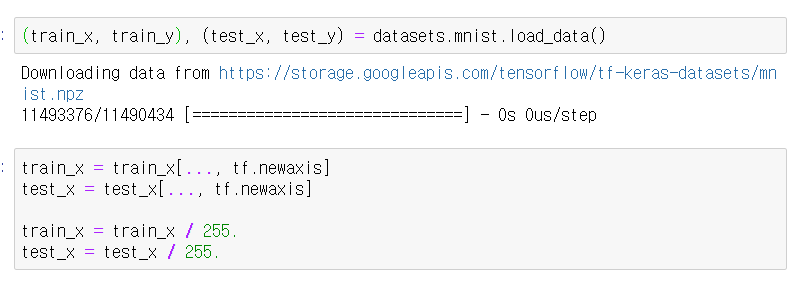
▶ Training

▶ Training
1. 학습한 모델을 확인해본다.

2. 결과 확인
2-1. 모델에 input할 데이터를 먼저 확인한다.

2-2. test셋을 모델에 넣기 위해 shape 조정


- predict나 evalutae은 변수에 영향을 안 줌. predict는 자동적으로 evaluate 모드로 변환되고, image들어가면 결과 나옴.
- pred에는 10개의 노드가 있는데, 노드의 값이 가장 높은것이 인공지능이 생각하는 답이다.
가장 높은 인덱스를 찾기 위해 np.argmax를 이용해보자.
3. np.argmax로 정답 예측

▶ Test Batch
train한 모델에 이젠 test셋을 넣어주자.
1. Batch로 Test Dataset 넣기

2. Batch Test Dataset 모델에 넣기

3. 결과 확인


- train 데이터 셋에서 7이 있어, 학습한 후에 test 데이터 셋의 7을 잘 맞추는 것을 확인할 수 있다.

- 예측 잘함. 위의 실습에서 test 셋은 학습을 시키지 않았는데도, 예측 결과가 잘 나왔다.
(새로운 데이터셋인데도 잘 맞춤)
'Study > AI&DeepLearning' 카테고리의 다른 글
| [PyTorch] Optimization & Training & Evaluating (0) | 2021.01.18 |
|---|---|
| [PyTorch] 데이터 불러오기 & Layer 이해하기 (0) | 2021.01.18 |
| Optimization & Training (Beginner / Expert) (0) | 2021.01.18 |
| 각 Layer별 살펴보기 (0) | 2021.01.11 |
| MNIST 불러오기 (0) | 2021.01.11 |
'Study/AI&DeepLearning' Related Articles
more




Comments