
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- leetcode 15
- airflow docker
- docker로 airflow 설치하기
- leetcode 121
- leetcode 5
- leetcode 344
- Hadoop
- leetcode 561
- 머신러닝
- Hortonworks Sandbox
- leetcode 238
- 데이터레이크와 데이터웨어하우스
- wargame.kr
- 빅데이터를 지탱하는 기술
- leetcode 234
- MapReduce 실습
- ctf-d
- 블로그 이전했어요
- 스파크 완벽 가이드
- 올바른 변수명 짓기
- 컴퓨터구조
- leetcode 49
- 배열
- leetcode
- webcrawler
- 문자열 조작
- Python
- leetcode 819
- leetcode 937
- leetcode125
- Today
- Total
HyeM
[컴퓨터구조]5주차_캐시기억장치 본문
캐시기억장치

캐시기억장치 :
주기억장치(RAM) 저장된 명령어 or 데이터 일부를 임시적으로 복사해서 저장하는 장치
(임시적으로 복사 = 자주 사용하는 명령어 저장했다가 cpu에 제공)
특징 :
- 주기억장치 보다 빠름 _ 명령어or 데이터 저장&인출 속도 UP
- 자주 사용되는 명령어들을 캐시에 저장해두어, CPU에 빠르게 제공
- 고속완충제역할을 하는 기억장치 _ 느린 주기억장치와 빠른 중앙처리장치(CPU)사이에서 속도 차이 줄여줌
캐시 기억장치는 왜 필요할까 ??
# 만약에 없다면 ?

동작 과정 :
cpu가 주기억 장치에 접근 → 주기억장치에서 정보 획득 → cpu의 명령어 레지스터 등에 저장 => SLOW 느림! (cpu -> 주기억장치 -> cpu)
~~~>비효율적임. 매번 cpu가 주기억장치에 접근해야됨. 이거 자체가 속도가 느림
# 그렇다면 있다면??

동작 과정 :
cpu가 주기억장치에 바로 접속하지 않고, 캐시기억장치를 먼저 조사한다.
(캐시 기억장치에는 주기억장치의 데이터의 일부가 저장되어 있음)
-> 만약, 캐시 기억장치에서 찾았다면 hit, 못 찾으면 miss 라고 함.
->hit경우에는 cpu로 바로 가져오면 되지만,
miss인 경우에는 주기억장치에서 원하는 데이터를 찾아와, 캐시기억장치에 저장후, cpu로 되돌아온다.
더 알아보기 _ miss(실패)
경우 : miss 실패; 캐시기억장치에서 원하는 데이터를 찾지 못함
< 실패상태 처리단계 >
1. 주기억장치에서 필요한 정보를 가져와 캐시기억장치에 전송함. (바로 cpu로 가져가는것이 아님)
2. 캐시기억장치에 보내진 정보를 다시 중앙처리장치(CPU)로 전송한다. ( 캐시기억장치에 이 데이터가 저장됨.)
( cpu -> cash로 필요한 데이터 있는지 검사,없으면 주기억장치 -> cash -> cpu )
(예시와 사진으로 더 자세히 살펴보자)
예시 : CPU가 1000번지의 워드가 필요한 경우 ( 워드 : cpu가 처리할 수 있는 단위 )

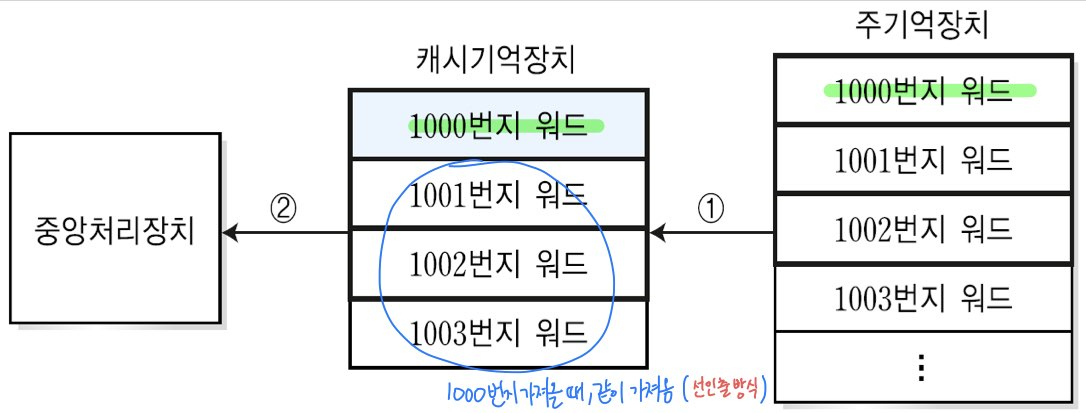
더 알아보기 _hit(성공)
경우 : hit 성공 ; 캐시기억장치에서 원하는 데이터가 있음
예시
: cpu가 1002번지의 워드가 필요한 경우
< 단계 >
1. 캐시기억장치에 1002번지의 워드를 저장하고 있는지 검사한다. 존재하면 , 적중상태(hit)이 됨
2. 그 정보를 중앙처리장치(CPU)로 전송한다. ( 주기억장치에 접근하지 않았음 )

더 알아보기 _ 주기억장치와 캐시기억장치 간의 정보 공유 단위

' CPU - 캐시기억장치 ' 간의 통신 단위는 워드
' 캐시기억장치 - 주기억장치 ' 간의 통신 단위는 블록
블록 : 여러개의 워드가 쌓여서 블록이 됨 .
워드 : cpu가 한 번에 처리할 수 있는 단위 ; 하나의 주소번지에 저장되는 데이터 단위
더 알아보기 _ 캐시기억장치의 구조
- 슬롯(slot) : 데이터 블록이 저장되는 장소
- 태그(tag) : 슬롯에 적재된 데이터 블록을 구분해주는 정보

캐시 기억장치의 적중률
적중률 :
캐시기억장치의 성능을 나타내주는 척도
적중률↑ == 데이터 액세스 속도 향상
적중률 계산 :

ex, 전체 메모리 참조를 10번해는데, ram에 접근하지 않고, 캐시메모리만 참조한게 10번이라면, 적중률 1임
주기억장치와 캐시기억장치에서 데이터를 인출하는데 소요되는 평균 기억장치 접근 시간 (Taverage)
Taverage = Hhit_ratio * Tcache + (1-Hhit_ratio) * Tmain
Tmain : 주기억장치 접근시간
Tcache : 캐시기억장치 접근 시간
Hhit_ratio : 적중률
(예제)
Tcache = 50ns, Tmain = 400ns일때,
적중률 증가에 따른 기억장치 접근 시간 계산
적중률 70%의 경우: Taverage = 0.7 * 50ns + 0.3 * 400ns = 155ns
적중률 80%의 경우: Taverage = 0.8 * 50ns + 0.2 * 400ns = 120n
적중률 99%의 경우: Taverage = 0.99 * 50ns + 0.01 * 400ns = 53.5n
==> 캐시기억장치의 적중률이 높을 수록, 주기억장치와 캐시기억장치에서 데이터를 인출하는데 소요되는 평균 기억장치에 접근하는 시간이 감소한다.
캐시기억장치 설계시 고려사항
01. 캐시기억장치의 크기(Size)
적당해야함 (1K~128K) 단어가 최적함 (크기가 크면, cash 안에서 데이터를 찾는데 그만큼 시간이 더 걸림)
캐시기억장치 크기 up, 적중률 up, But 평균접근시간 up, 비용 up
02. 인출방식
: RAM에서 캐시기억장치로 명령어 or 데이터 블록 인출하는 방식 ( RAM -> Cash로 인출 방식)
방법 1. 요구인출방식(Demand-Fetch) : cpu가 현재 필요한 정보만 오직 RAM에서 인출해, 캐시기억장치에 저장
방법 2. 선인출방식 (PreFetch) : cpu가 현재 필요한 정보 + 앞으로 필요할 것으로 예측 되는 것 을 캐시기억장치에 저장함
ㄴ주기억장치에서 명령어 or 데이터 인출시, 필요한 정보와 이웃한 위치의 정보도 함께 인출.
03. 사상함수
사상(mapping) :
주기억장치와 캐시기억장치 사이에서 정보를 옮기는 것

사상방법 :
-
직접사상
주기억장치의 데이터 블록을 캐시기억장치에 저장할 때, 다음의 주소 변환을 거친다.
(주기억장치) 데이터 블록 주소 = (캐시기억장치) 데이터 블록 슬롯번호(주소) + 데이터 블록 태그
~>캐시기억장치에서 데이터 블록 인출시, 데이터 블록의 슬롯 번호에 해당하는 슬롯만 검색하면 됨.
장점 : 사상과정이 간단함
단점 : 동일 슬롯 번호를 갖으면, 태그가 다른 데이터 블록에 대한 반복적 접근함 -> 반복적 접근은 적중률 떨어뜨림.
예시는 더보기 클릭
단계 1. CPU가 00001번지 블록을 필요로 하는 경우 ( 1블록 = 1단어 )

1. cpu가 RAM의 00001번지의 데이터를 원하여, 캐시기억장치에 접근하지만, 그 데이터를 찾을 수 없음. MISS)
2. 주기억장치에 접근하여 00001번지의 데이터를 가져온다.
3. 캐시기억장치는 주소의 앞의 2개를 tag로 하여 데이터와 함께 저장한다.
4. 그 후, cpu로 원하던 데이터를 가져간다.
단계 2. cpu가 00010번지 블록을 필요로 하는 경우

1.cpu가 RAM의 00010번지의 데이터를 원하여, 캐시기억장치에 접근하지만, 그 데이터를 찾을 수 없음 MISS)
2. 주기억장치에 접근하여 00010번지의 데이터를 가져온다.
3. 캐시기억장치는 주소의 앞의 2개를 tag로 하여 데이터와 함께 저장한다.
40 그 후, cpu로 원하던 데이터를 가져간다.
문제점 : cpu가 태그가 00인 데이터를 찾을 때, 혼동함.
단계 3. cpu가 10001번지 블록을 필요로 하는 경우

1.cpu가 RAM의 10001번지의 데이터를 원하여, 캐시기억장치에 접근하지만, 그 데이터를 찾을 수 없음 MISS)
2. 주기억장치에 접근하여 10001번지의 데이터를 가져온다.
3. 캐시기억장치는 주소의 앞의 2개를 tag(10)로 하여 데이터와 함께 저장한다.
40 그 후, cpu로 원하던 데이터를 가져간다.
단계4. cpu가 00010번지 블록을 필요로 하는 경우

1. cpu가 RAM의 00010번지의 데이터를 원하여, 캐시기억장치 접근한다. 데이터가 있으니, 바로 cpu로 되돌아간다. (HIT)
-
연관사상
캐시 슬롯번호에 상관없이, 주기억장치의 데이터 블록을 캐시 기억장치의 임의의 위치에 저장
(주기억장치) 데이터 블록 주소 = (캐시기억장치) 데이터 블록 태그
~> 캐시기억장치에서 데이터 블록 인출시, 모든 슬롯 검색

-
집합 연관 사상
직접사상 + 연관사상을 조합한 방식
캐시는 v개의 집합들로 나누어지고, 각 집합들을 k개의 슬롯들로 구성됨
By 직접 사상방식, v개의 집합들중 하나의 집합 선택 (집합번호 이용)
By 연관 사상방식, 선택한 집합내에 있는 k개의 슬롯중에서 하나의 슬롯 선택
(주기억장치) 데이터 블록 주소 = (캐시기억장치) 데이터 블록집합번호 + 데이터 블록 태그

04. 교체알고리즘
캐시기억장치의 모든 슬롯이 데이터로 채워져 있는 상태(Full)인 상태에서, 실패(miss)일때는
주기억장치로부터 새로운 데이터 블록을 캐시기억장치로 옮겨야 한다.
이때 캐시기억장치는 full 상태이므로, 어느 슬롯의 데이터를 제거할지 결정하는 방식이 필요하다.
( 직접사상 : 교체알고리즘 필요 x ; 연관&집합 연관 사상 : 교체 알고리즘 필요)
종류 :
LRU (Least Recently Used): 최소 최근 사용 알고리즘 _ 최근에 가장 적게 이용한거 삭제
LFU (Least Frequently Used): 최소 사용 빈도 알고리즘 _ 가장 적은 빈도로 사용한거 삭제
FIFO (First In First Out): 선입력 선출력 알고리즘 _ 먼저 들어간 데이터 삭제
RANDOM: 랜덤
05. 쓰기 정책
캐시기억장치에 데이터를 쓰는 방식에는 기록하는 시점에 따라 2가지로 나뉜다.
◈ 즉시 쓰기(Write-though) 방식
cpu에서 생성되는 데이터 블록을 캐시기억장치와 주기억장치에 동시에 기록
( cpu에서 연산하고 나서 그 결과를 바로 캐시기억장치와 주기억장치에 둘 다 기록한다. )
장점 : 데이터의 일관성 보장
단점 : 매번 쓰기 동작 발생할 때마다, 캐시기억장치 & 주기억장치에 접근 증가, 쓰기 시간 증가
◈ 나중 쓰기(Write-back) 방식
캐시기억장치에 기록한 후, 기록된 블록에 대한 교체 발생시, 주기억장치에 기록
장점 : 즉시쓰기방식과 달리, 주기억장치에 기록하는 동작 최소화
단점 : 데이터의 일관성 보장x ( 캐시기억장치와 주기억장치의 데이터가 서로 일치 않을 수 있음)
06. 블록 크기와 캐시기억장치의 수
> 블록 크기 :
블록 크기 크면? _ 한번에 많은 정보 읽어올 수 있음, but, 블록 인출 시간 증가
_ 캐시기억장치에 적재할 수 있는 블록의 수가 감소 -> 블록들이 더 빈번히 교체됨
일반적인 블록의 크기 : 4~8단어가 적당
> 캐시의 수 :
시스템의 성능 향상을 위해, 다수의 캐시기억장치를 사용하는 것이 보편적
캐시기억장치들은 계층적 구조나 기능적 구조로 설치함
출처 :
2019 컴퓨터 구조 호준원 교수님 강의노트
디지털논리와 컴퓨터 설계, Harris et al. (조영완 외 번역), 사이텍미디어, 2007,
컴퓨터 구조와 원리 (비주얼 컴퓨터 아키텍처), 신종홍 저, 한빛미디어, 2011
문제
1. 다음 빈칸에 들어갈 말을 쓰시오.
캐시기억장치는 __(A)__와 __(B)__사이에서 고속완충제 역할을 해준다.
(A)에서 원하는 데이터가 캐시기억장치에 있는 경우 HIT이라고 하고, 없는 경우는 MISS라고 표현한다.
(A) : _____(B) : _________
2. 다음에서 주기억장치와 캐시기억장치에서 데이터를 인출하는데 소요되는 평균 기억장치 접근 시간을 계산하시오.(Taverage계산)
( 단, 주기억장치 접근 시간 : 300ns , 캐시기억장치 접근시간 : 60ns , 적중률 70% 이다. )
3. 다음 중 옳지 않은 설명을 고르시오.
|
1. 캐시기억장치의 크기가 크면 , 그 안에서 데이터를 찾는데, 시간이 걸리므로, 적당해야 한다. 2. RAM에서 캐시기억장치로 명령어를 인출할 때, 앞으로 필요할 정보도 미리 인출해 캐시에 저장하는 방법을 '선인출방식'이라고 한다. 3. 연관사상방식은, 캐시기억장치의 태그 부분에 데이터 블록 주소를 그대로 저장한다. 4. 집합 연관 사상은, 캐시기억장치를 n개의 태그로 나누어, 각 태그들의 묶음에는 여러개의 슬롯이 있다. 5. 직접 연관사상은, 주기억장치의 데이터블록 주소를 슬롯번호와 태그로 나누어 저장한다.
|
4.~5 다음을 o,x로 구분하여라
(1) 나중쓰기 방식은, 캐시기억장치에 기록한 후, 기록된 블록의 교체가 일어날 때, 주기억장치에 기록하는 방식으로, 데이터 손실이 발생할 수도 있다.
(2) 블록의 크기가 크면 클수록 많은 정보를 읽어 올수 있고, 일반적인 블록의 크기는 15~18단어가 적당하다.
6. 다음은 어떤 사상 방식을 설명하는 것인가?
교체 알고리즘 필요하지 않고, 슬롯번호와 태그를 이용하여, 캐시기억장치에 저장한다. 이는 동일한 슬롯번호를 갖게 될 때의 문제점을 지니고 있다.
답 : _________
7. 다음에서 설명하는 교체 알고리즘을 연결하시오.
(1) 최근에 가장 적게 이용한 데이터를 삭제한다.
(2) 먼저 들어간 데이터를 삭제한다
(3) 가장 적은 빈도로 사용한 데이터를 삭제한다.
<보기> RANDOM, FIFO, LFU, LRU
문제 정답은 더보기 클릭
문제 정답
1. 다음 빈칸에 들어갈 말을 쓰시오.
캐시기억장치는 __(A)__와 __(B)__사이에서 고속완충제 역할을 해준다.
(A)에서 원하는 데이터가 캐시기억장치에 있는 경우 HIT이라고 하고, 없는 경우는 MISS라고 표현한다.
(A) : CPU(중앙처리장치)
(B) : 주기억장치
++추가: hit인 경우에는 , 주기억장치에 접근할 필요가 없지만, MISS인 경우에는 주기억장치에 접근하여 데이터를 찾아, CASH에 저장단계를 거쳐 CPU로 돌아온다.
2. 다음에서 주기억장치와 캐시기억장치에서 데이터를 인출하는데 소요되는 평균 기억장치 접근 시간을 계산하시오.(Taverage계산)
( 단, 주기억장치 접근 시간 : 300ns , 캐시기억장치 접근시간 : 60ns , 적중률 70% 이다. )
Taverage= (적중률)*(캐시기억장치 접근시간) +(1-적중률)*(주기억장치접근시간)이다.
이를 계산하면, 0.7*60ns + 0.3*300ns = 42+90 = 132ns이다.
+ 캐시기억장치의 적중률이 높을 수록, 주기억장치와 캐시기억장치에서 데이터를 인출하는데 소요되는 평균 기억장치 접근시간이 낮아진다.
3. 다음 중 옳지 않은 설명을 고르시오.
| 1. 캐시기억장치의 크기가 크면 , 그 안에서 데이터를 찾는데, 시간이 걸리므로, 적당해야 한다. 2. RAM에서 캐시기억장치로 명령어를 인출할 때, 앞으로 필요할 정보도 미리 인출해 캐시에 저장하는 방법을 '선인출방식'이라고 한다. 맞다. 이와 반대인 '요구인출방식'은 현재 필요한 정보만 RAM에서 인출하여, 캐시기억장치에 저장한다. 3. 연관사상방식은, 캐시기억장치의 태그 부분에 데이터 블록 주소를 그대로 저장한다. 맞다. 그래서 연관사상방식은, 주소를 찾을때 시간이 걸리므로, 비효율적이다. 4. 집합 연관 사상은, 캐시기억장치를 n개의 태그로 나누어, 각 태그들의 묶음에는 여러개의 슬롯이 있다. 아니다. 집합연관사상은 , 캐시기억장치를 n개의 집합번호로 구분하여 집합으로 나뉘고, 각 집합안에는 여러개의 슬롯들로 구성된다. 5. 직접 연관사상은, 주기억장치의 데이터블록 주소를 슬롯번호와 태그로 나누어 저장한다. 맞다. 그래서, 캐시기억장치에서 데이터블록 인출시, 데이터 블록의 슬롯번호에 해당하는 슬롯만 검색하면 된다. |
4.~5 다음을 o,x로 구분하여라
(1) 나중쓰기 방식은, 캐시기억장치에 기록한 후, 기록된 블록의 교체가 일어날 때, 주기억장치에 기록하는 방식으로, 데이터 손실이 발생할 수도 있다. ( O , X )
나중쓰기 방식은 즉시쓰기방식과 달리, 주기억장치에 기록하는 동작 최소화하여 효율적이지만, 데이터의 일관성 보장되지 않는다는 단점이 있다. ( 즉, 손실이 발생할 수 있음)
(2) 블록의 크기가 크면 클수록 많은 정보를 읽어 올수 있고, 일반적인 블록의 크기는 15~18단어가 적당하다. (X)
아니다. 블록의 크기가 크면 많은 정보를 읽어올 수 있긴하지만, 일반적인 블록의 크기는 4~8단어가 적당하다. ( 많으면, 블록인출 시간 증가)
6. 다음은 어떤 사상 방식을 설명하는 것인가?
교체 알고리즘 필요하지 않고, 슬롯번호와 태그를 이용하여, 캐시기억장치에 저장한다. 이는 동일한 슬롯번호를 갖게 될 때의 문제점을 지니고 있다.
답 : 직접 사상
직접사상은 교체알고리즘이 필요없지만, 집합연관사상과 연관사상방식은 필요하다.
7. 다음에서 설명하는 교체 알고리즘을 연결하시오.
(1) 최근에 가장 적게 이용한 데이터를 삭제한다. LRU ( LEAST RECENTLY USED)
(2) 먼저 들어간 데이터를 삭제한다 FIFO(FIRST IN FIRST OUT)
(3) 가장 적은 빈도로 사용한 데이터를 삭제한다. LFU(LEAST FREQUENTLY USED)
<보기> RANDOM, FIFO, LFU, LRU
RANDOM : 랜덤
FIFO (First In First Out): 선입력 선출력 알고리즘
LFU (Least Frequently Used): 최소 사용 빈도 알고리즘
LRU (Least Recently Used) : 최소 최근 사용 알고리즘
보조기억장치, 입력과 출력, 시스템 버스
추가 문제
1. 보조기억장치에 대한 설명 중 옳지 않은 것은?
| 1. 순차적 접근은 데이터가 저장되는 순서에 따라 접근 순서가 결정되고, 자기테이프와 카세트 테이프가 대표적이다. 2. 직접 접근의 접근 시간은 원하는 데이터의 위치와 이전 접근 위치에 따라 결정된다. 3. 보조기억장치의 평가기준 중, 전송시간은 데이터가 보조기억장치에서 인출돼서 주기억장치로 전송되는 걸리는 시간을 말한다. 4. 자기 디스크는 순차적 접근과 직접 접근이 모두 가능하다. 5. 자기 디스크는 디스크 팔을 이용하여, 원형평판의 데이터를 읽고 쓴다. |
2. 다음을 설명하는 입출력 장치 제어 기법은 무엇인가?
대용량의 데이터를 이동시킬 때 효과적인 기술로, 중앙처리 장치는 개입하지 않는다. __??_의 내부 구조는 주소레지스터, 데이터 레지스터, 계수레지스터 등으로 구성되어 있다.
3. 설명과 맞는 버스를 연결하시오.
1) 컴퓨터 시스템 구성 장치들 사이에서 데이터를 전송하는 용도로 사용되는 선들의 집합이다.
2) cpu가 주기억장치의 특정 주소로 데이터를 쓰거나, 읽기 동작을 할때, 주기억장치의 주소를 전송하기 위한 선들의 집합이다.
4. o,x로 구분하시오.
1) 주소버스는 양방향 전송이 가능하고, 데이터 버스도 양방향 전송이 가능하다.
2) 단일 버스 통합형 DMA는 시스템 버스를 한번만 사용하고, 입출력 버스를 이용한 DMA 방식또한 한번만 시스템 버스를 사용한다.
5. 중앙처리 장치와 관련되지 않은 신호를 고르시오.
1) 기억장치 쓰기 신호
2) 인터럽트 요청 신호
3) 입출력 쓰기 신호
4) 전송 확인 신호
5) 입출력 읽기 신호
추가 정답
1. 보조기억장치에 대한 설명 중 옳지 않은 것은?
| 1. 순차적 접근은 데이터가 저장되는 순서에 따라 접근 순서가 결정되고, 자기테이프와 카세트 테이프가 대표적이다. 맞다. 순차적 접근 시간은 데이터의 저장 위치에 따라 다르다. 2. 직접 접근의 접근 시간은 원하는 데이터의 위치와 이전 접근 위치에 따라 결정된다. 맞다. 직접접근은 원하는 데이터가 저장된 기억장소 근처로 이동하여, 순차적 검색을 통해 원하는 데이터에 접근한다. 3. 보조기억장치의 평가기준 중, 전송시간은 데이터가 보조기억장치에서 인출돼서 주기억장치로 전송되는 걸리는 시간을 말한다. 맞다 + 접근시간은 보조기억장치에서 데이터를 판독&기록하는데 걸리는 시간으로 전송시간과 다름을 구분하자. 4. 자기 디스크는 순차적 접근과 직접 접근이 모두 가능하다. 맞다. 자기디스크는 양면이 자성재료로 피복되어 있는 원형 평판으로 속도가 빠르고 기억용량이 크다. 5. 자기 디스크는 디스크 팔을 이용하여, 원형평판의 데이터를 읽고 쓴다. 아니다. 자기디스크는 헤드를 이용하여, 원형 평판의 데이터를 읽고 쓴다. 디스크 팔은 헤드를 이동시키는 장치로 옳지 않다. |
답 : 5
2. 다음을 설명하는 입출력 장치 제어 기법은 무엇인가?
대용량의 데이터를 이동시킬 때 효과적인 기술로, 중앙처리 장치는 개입하지 않는다. __??_의 내부 구조는 주소레지스터, 데이터 레지스터, 계수레지스터 등으로 구성되어 있다.
답 : 직접 기억장치 액세스 (DMA)
DMA방식은 DMA 제어기가 모든 입출력동작을 전담하고, cpu는 전송의 시작과 마지막에만 관여한다.
3. 설명과 맞는 버스를 연결하시오.
1) 컴퓨터 시스템 구성 장치들 사이에서 데이터를 전송하는 용도로 사용되는 선들의 집합이다.
=> 데이터 버스; 데이터 버스는 양방향 전송이 가능하고, 데이터 버스의 버스의 폭은 연결된 장치들 사이에서 한번에 전송되는 비트들의 수를 말한다.
2) cpu가 주기억장치의 특정 주소로 데이터를 쓰거나, 읽기 동작을 할때, 주기억장치의 주소를 전송하기 위한 선들의 집합이다.
=>주소버스; 주소 버스의 비트수는, cpu가 접근할 수 있는 기억장치의 주소수를 결정하고, 폭이 16비트인 경우엔 주소지정 가능한 최대 기억장소의 수는 2^16이 된다.
4. o,x로 구분하시오.
1) 주소버스는 양방향 전송이 가능하고, 데이터 버스도 양방향 전송이 가능하다.
아니다. 주소 버스는 단방향전송만 가능하고, 이의 방향은 cpu에서 주기억장치 및 입출력 모듈로의 방향만 가능하다.
2) 단일 버스 통합형 DMA는 시스템 버스를 한번만 사용하고, 입출력 버스를 이용한 DMA 방식 또한 한번만 시스템 버스를 사용한다.
맞다. 단일 버스 통합형 DMA방식과 입출력 버스를 이용한 DMA 방식 둘 다 시스템 버스를 한 번만 사용한다. 다만, 단일버스 분리식DMA는 데이터 전송을 위해 시스템 버스를 두 번씩 사용해야 한다.
5. 중앙처리 장치와 관련되지 않은 신호를 고르시오.
1) 기억장치 쓰기 신호
2) 인터럽트 요청 신호
3) 입출력 쓰기 신호
4) 전송 확인 신호
5) 입출력 읽기 신호
답: 2. 인터럽트 요청신호는 인출력 장치가 인터럽트를 cpu에 요청했음을 알리는 신호로 인터럽트 버스에서 사용되는 제어 신호이다 ( 인터럽트 버스 : 인터럽트 동작을 위한 제어 신호 선들의 집합)
기억장치 쓰기 신호 : cpu와 주기억장치 관련신호, 버스에 적재된 데이터를 기억장치에 저장하는 제어신호
입출력 쓰기 신호 : cpu와 입출력장치 관련 신호, 버스에 적재된 데이터를 지정된 입출력장치로 출력시키는 제어신호
전송확인 신호 :cpu와 입출력장치 관련 신호, 데이터 전송 동작이 완료됨을 알려주는 신호
입출력 읽기 신호 : cpu와 입출력장치 관련 신호, 지정된 입출력 장치에서 데이터를 읽어서 데이터 버스에 적재시키는 제어 신호
'Study > Computer Architecture' 카테고리의 다른 글
| [컴퓨터구조]6주차_MIPS구조 (0) | 2020.06.09 |
|---|---|
| [컴퓨터구조]4주차_서브루틴과 명령어 구분 (0) | 2020.05.30 |
| [컴퓨터구조]3주차(2)_메모리 구조 & 레지스터 종류 (0) | 2020.05.23 |
| [컴퓨터구조]3주차(1)_명령어 실행 기법 (0) | 2020.05.19 |
| [컴퓨터구조]2주차(2)_어셈블리 프로그램 예제 (0) | 2020.04.18 |



