
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 컴퓨터구조
- 머신러닝
- wargame.kr
- leetcode 937
- leetcode 234
- 올바른 변수명 짓기
- webcrawler
- leetcode 49
- leetcode125
- leetcode 238
- leetcode 5
- leetcode 121
- docker로 airflow 설치하기
- leetcode 344
- leetcode 15
- 빅데이터를 지탱하는 기술
- 데이터레이크와 데이터웨어하우스
- 블로그 이전했어요
- airflow docker
- 배열
- ctf-d
- Python
- 문자열 조작
- Hadoop
- leetcode
- leetcode 819
- leetcode 561
- MapReduce 실습
- 스파크 완벽 가이드
- Hortonworks Sandbox
- Today
- Total
HyeM
[Python]WebCrawler2_웹툰 이미지 크롤링 본문
WebCrawler2_ WebtoonCrawler 웹툰 이미지 크롤링
※ 이 프로그램은 개인적인 학습을 위해 제작한 것입니다. 이를 악의적인 목적으로 사용하지 마세요. ※
== 기능 ==
-
해당 웹툰의 페이지에서, 제목과 회차 정보의 문자열을 추출하여, 폴더를 만든다. ( 웹툰 제목의 폴더안에 회차별로 폴더 존재)
-
회차별 폴더 안에는 한 회차의 이미지들이 저장된다. 한페이지의 웹툰은 10개가 있으므로, 크롤러 실행시 10개의 웹툰회차가 저장된다.
== 실행 화면 ==


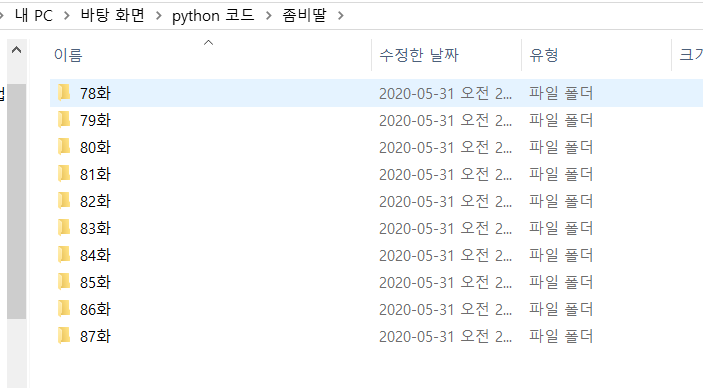

== 프로그램 로직 ==
-
해당 웹툰 페이지 HTML 파싱하기
-
웹페이지 html에서 웹툰 이름 필터링 하기
-
웹툰 파일명 파일 만들기
-
회차별 이름 필터링 하기 (반복)
-
회차별 파일 만들기 (반복)
-
이미지 다운받기 (반복)
4~ 6번 과정은 회차별 폴더를 만들고 그 안에 이미지를 다운로드 하는 과정으로, 반복문을 통해 구현하였다.
== 프로그램 코드 설명 ==
>> 사용한 모듈

파싱을 위한 beautiful 모듈, 운영체제 기능제공하는 os 모듈, sub()함수를 위한 re모듈
>>1. 해당 웹툰 페이지 HTML 파싱 하기

웹 페이지 요청 및 파싱 ( html 문자열로 가져오기 위함)
>>2. 웹페이지 html에서 웹툰 이름 필터링하기

- 11,12 line : h2 태그만 모두 찾아, 두번째 정보만 가져와 string으로 타입 변환 해준다.

- 13 line : 정규 표현식을 이용하여, 위의 코드에서 <span class="wrt_nm"> .....이윤창</span> 이 코드를 제거한다.
<span.*?>.*?</span> 해석 : <span 으로 시작하고 뭔가 한글자 있고, >로 끝나고 중간에 문자(들)있고, </span>으로 끝나는 문자를 제거한다.
네번째인수 0 : 조건을 만족하는 모든 문자열 삭제
다섯번째 인수 re.I | re.S : re.I는 대소문자 구별없이 매치 수행할때 이용, re.S는 개행문자도 ','로 매칭된다. (기본값은 '.'은 개행 문자와 매칭되지 않음)

++ re.sub(패턴, 치환할 값, 문자열) , import re 필요
- 14 line : 태그 제거 해준다.
<.+?>정규식 해석 : <로 시작하고 뒤에 한글자 이상있고 >로 끝나면 sub()함수로 삭제한다.

- 15line : 공백, 엔터 탭키를 제거 해준다.

>>3. 웹툰 파일명 파일 만들기

>>4. 회차별 이름 필터링 하기 (반복)

24 line : 페이지 html코드중, class가 title인 td 태그들만 추출한다. ( 여기 안에 회차 정보 들어있음)
26 line : 반복문을 돌며, 회차별로 접근가능하게 해준다.
27 line : 추출된 회차 td 태그중 text만 빼온다. ( title이 회차이름)
>>5. 회차 파일 만들기 (반복)

>>6. 이미지 다운받기(반복)

34,35 line : 회차별 웹툰 링크로 넘어가서 코드를 가져와 result2변수에 저장한다.
36 line : 본문 내용의 tag만 필터링 한다. ( 이 안에는 이미지 링크들이 있음 )
39 line : 이미지 저장시, 하나씩 처리해야 하므로 반복문 돌림
40 line : 이미지 다운 받는 링크
43 line : 파일 다운 경로&이름의 다운받는 경로
45~49 line : 51번째 줄의 이미지 다운로드 받을때, 생기는 오류를 우회하기 위한 코드 추가
네이버에서 서버인지 봇인지 판별하는데, header에 user-agent 정보를 넣어 사람인것처럼 속이는 코드 이다.
== 코드 ==
https://github.com/KimHyeMin0207/Web-Crawler/blob/master/WebtoonCrawler.py
KimHyeMin0207/Web-Crawler
Contribute to KimHyeMin0207/Web-Crawler development by creating an account on GitHub.
github.com
[참고]
정규식에 관한 정보 : http://zeany.net/46
'Programming > Python' 카테고리의 다른 글
| [Python]GameMacro_순발력테스트 매크로 (0) | 2020.06.07 |
|---|---|
| [Python]WebCrawler1_홈페이지URL출력 (0) | 2020.05.30 |
| [Python]Up&Down 게임 (0) | 2020.05.30 |
| [Python]리스트 함수 (0) | 2020.04.12 |
| [Python]문자열 함수 (0) | 2020.04.12 |

